The math of bloom filters
Written by
link: https://www.bytedrum.com/posts/bloom-filters/ Much has been already been written about bloom filters for example this very practical high quality blog post
A bloom filter is a probabilistic data structure that answers whether a given element has been seen or not.
It answers that it has not seen an element deterministically, and answers that it has seen an element probabilistically. This means it should only be used in cases where false positives are tolerated and false negatives are not tolerated.
A good use case is optimizing data fetching in databases. If we had a database that stores rows of data
in pages, a Bloom filter for each page could be built, and for a one point query like SELECT * FROM table WHERE id = 28272831,
it could check whether the id might exist in a page without actually loading the page into memory.
If the Bloom filter returns a positive result, the page would be loaded and checked again. This allows to skip unnecessary disk reads and scan for values more efficiently and is specially useful when typical data structures like b-trees become too expensive in large amounts of data or when loading data from disk is very expensive.
The latter is the case of TimescaleDB, where data is split into batches and batches are further compressed. Searching for a particular value is expensive (also common in other OLTP systems), as the batches needs to be loaded into memory and decompressed.
TimescaleDB stores Bloom filters per compressed batch, for selected columns, so it can skip decompressing batches that definitely do not contain the searched value. which for some queries can yield up to 6x improvement [1].
The anatomy of a bloom filter
At heart, a bloom filter is just a bitarray,

Math
To start gently, let us first consider a perfect square dice, it has six possible values, from 1 to 6.

The probability of obtaining any value is:
If the dice is thrown twice, the probability to obtain the values {3, 6} is:
Considering that every throw is an unrelated event, 36 is obtained by multiplying all possible values (6) by every throw.
This function has the rule:
Where n is the number of times a dice is thrown.
Probability of a bit being 0
Rolling a dice and bloom filters share some similarities, every time a dice is rolled is like inserting a new value, and the size of the bloom filter is its length a.k.a. the number of bits it can hold.
The probability of hitting any bit after an insertion is:
If the probability of something not happening is 25%, the probability of it happening is:
Following this logic, the probability of not hitting a bit after an insertion is:
Now, not only one insertion happens per value, there are k * n insertions, where k is the number of hash functions and n the number of insertions.
Probability of a bit being 0 after k*n insertions
Applying the same rule, the probability that a bit is 1 after n insertions is:
The probability of having an empty bit can be further refined, by studying its limit.
There is a well known characterization of the exponential function that tells us that for big m values, it approximates to e
It looks particularly similar to the p0 function, we can obtain an e based rule by working out the exponents:
Obtaining:
Probability of a bit being 0 after k*n insertions for large values
And consequently, the probability that a bit is 1 is 1 - p:
False positives
One issue we mentioned earlier about bloom filters are false positives. They can happen when a value's hash not in the filter is the same as a value in the filter by pure chance.
For this to happen, every hash calculation (k) has to return that the bit is 1:
probability of false positive
For a 1kB (8192 bits) bloom filter with k=2, these are the probabilities:
| n | p false positive |
|---|---|
| 100 | 0.058% |
| 250 | 0.352% |
| 500 | 1.318% |
| 750 | 2.789% |
| 1000 | 4.689% |
| 1500 | 9.443% |
| 2000 | 14.916% |
| 3000 | 26.927% |
| 4000 | 38.820% |
| 5000 | 49.570% |
We have seen so far that hashes (k) and size (m) play a crucial role in false positives, something that we can optimize for
We want to find the optimal number of hash functions k, that is, the value of k that minimizes the false-positive probability.
We start from the approximate false-positive probability of a Bloom filter:
To minimize p, we minimize \ln p instead. This works because the natural logarithm is strictly increasing, so it preserves the location of the minimum while making the expression easier to differentiate.
At the optimal value, the derivative is zero, since no increases or decreases happen.
The resulting equation is transcendental because the variable appears inside logarithms, which makes it harder to solve with ordinary algebraic manipulations.
Notice how similar both sides are, where it looks like x = 1 - x. If both sides of the equations are painted the symmetry can be seen:
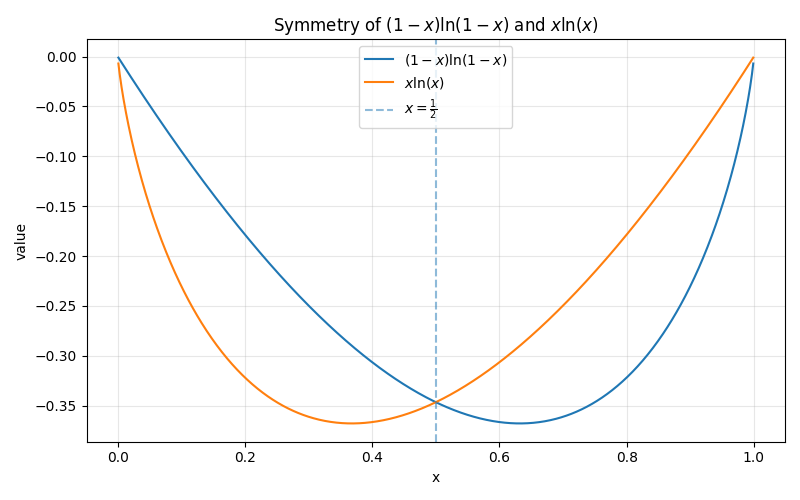
Therefore:
This tells us that the filter optimal state is 1/2, which is interpreted: The filter is the most efficient when half of its bits are still 0, and the other half are 1. If too few bits are set, the filter is underused; if too many are set, it becomes saturated and false positives rise quickly.
Finally solving the equation:
Optimal number of k
References
1. B. Purcell. "Speed Without Sacrifice: 2500x Faster Distinct Queries, 10x Faster Upserts, Bloom Filters and More in TimescaleDB 2.20," Tiger Data Blog Accessed: Apr. 24, 2026. [Online.] Available: https://www.tigerdata.com/blog/speed-without-sacrifice-2500x-faster-distinct-queries-10x-faster-upserts-bloom-filters-timescaledb-2-20
2. E. W. Weisstein. "e," Wolfram MathWorld Accessed: Apr. 24, 2026. [Online.] Available: https://mathworld.wolfram.com/e.html
Excerpt on reality: All the math we have seen so far is the perfect idealization of the problem, as when we calculate the probability of rolling a dice, we assume that the dice is a perfect cube with perfectly distributed weight and that it is perfectly thrown, in real life this is not true. This is the case with hash calculations, we assume them to be perfectly isolated and perfectly random, while in reality this might not be the case, different hash algorithm might obtain entropy from the same shared entropy pool, meaning one hash calculation could affect the other. Also hash calculation are considered to work, timescaledb once broke bloom filter due to poor hash calculation quality TODO INVESTIGATE.