Ingesting parquet to CrateDB: optimizing from 316.90s to 34s with Rust
Written by
Parquet has become the main format for modern data engineering; I would even argue that most companies right now use it in some shape or form, it has become what JSON is to web dev.
Almost all popular data manipulation and data analysis tools support it, just to name a few: Spark, Pandas, Polars, DuckDB, Delta lake...
The format is very efficient in terms of storage, for example, this ~3M rows dataset Yellow taxi trip - January 2024 takes:
- 48MiB in Parquet
- 342MiB in CSV
- 1.2GiB in JSON
- 510MiB in PostgreSQL 16.1 (Debian 16.1-1.pgdg120+1)
- 225MiB in CratDB 5.10
One of the first things that I was interested when I joined CrateDB was ingesting parquet files, the database does not implement it natively; in fact, few SQL databases natively support ingesting the format, some claim they do, but the ingestion is either in beta or actually way more limited than they make you believe.
The goal of this post is to load Parquet as fast as possible without any data loss. While this is going to be for CrateDB, it will probably translate well to other SQL databases.
There are three possible bottlenecks when ingesting data to a database the client, the server and the physical link between them: the network.
For these tests we’re going to use
- CrateDB CrateDB 5.9.3 (built f542b18/NA, Linux 5.15.0-125-generic amd64, OpenJDK 64-Bit Server VM 22.0.2+9)
- Server Ubuntu 22.04.2 LTS x86_64 - 5.15.0-125-generic - Intel i7-7700K (8) @ 4.500GHz - 16GB RAM
- Client Arch Linux x86_64 - 6.11.6-arch1-1 - 13th Gen Intel i7-13700KF (24) @ 5.300GHz - 32GB RAM
- Link between client-server is a 10m ethernet CAT5e cable through a 1GiB/s switch.
On the server side, there are many things that we can do to improve ingestion performance [1] [2], increase the number of nodes, remove replication, remove indexing, having a faster disk, a better cpu... but for the sake of my limited time we are going to focus, on the bottleneck that's mostly related to my job, client side.
For every 'solution' we try, we are going to log memory (GiB), cpu (%), upload speed (Mbps) and data integrity using a custom Python script [3]
Disclaimer:
- Benchmarking is hard [4].
- I'm going to run everything a few times and post one result, not the averages.
Also, I'm going to try to solve this problem as I write this post, so new ideas will appear. I might not find the most efficient solution right away.
Polars
The first thing that comes to my mind is to use Polars, which is very straight forward:
import polars CRATE_URI = 'crate://192.168.88.251:4200'FILE_PATH = '/data/taxi_01_24.parquet' df = polars.read_parquet(FILE_PATH) df.write_database( connection=CRATE_URI, table_name='ny_taxi', if_table_exists='append')
Results
- Time: 316.90s (5.26 minutes)
- Avg upload speed: 1.93Mb/s - max(2.8)
- Avg memory usage: 6.33Gb - max(6.67)
- Avg cpu usage: 1.37% - max(7.8)
- Avg throughput: 2964624 rows / 316.90 = 9355.18rows/s
High memory usage indicates that the whole file is loaded into memory. Cpu usage is low as well, not that I expect it to be higher, the only 'heavy' computation that is done is transposing columnar data into rows and serialization. Everything was executed in one process.
Looking at the upload speed, I don't think its properly batched (or they’re small), it's fairly low and not consistent as it has some troughs.
In conclusion, it takes too long (~6 minutes) and too much memory, we need to explore more options.
Trying low_memory=True yielded the same results.
Polars - Lazyframe + Batched
We could use a LazyFrame to use batches, so instead of loading everything to memory, we will only load smaller chunks of rows.
Let's try batches of 50k and 100k
import polars CRATE_URI = 'crate://192.168.88.251:4200'FILE_PATH = '/data/taxi_01_24.parquet'lazy_frame = polars.scan_parquet(FILE_PATH) batch_size = 100_000 # Number of rows per batch for batch in (lazy_frame .collect(streaming=True) .iter_slices(n_rows=batch_size)): batch.write_database( connection=CRATE_URI, table_name='ny_taxi', if_table_exists='append' )
Results
- Time: 315.88s (5.26 minutes)
- Avg upload speed: 1.94MiB/s - max(2.78)
- Avg memory usage: 0.96GiB - max(0.97)
- Avg cpu usage: 1.66% - max(4.9)
- Avg throughput: 2964624 rows / 315.88 = 9385.18rows/s
We dramatically decreased memory consumption, since only a batch will live in memory at the same time. The program is still being run in a single process and underutilizing the CPU, we can see many spikes and idle time.
I suspect that Polars is leveraging something like arrow's ParquetRecordBatchReaderBuilder, one of the many constructs to read parquet efficiently with batches.
The time taken is still the same as the non-batched solution.
Batch size of 50_000:
- Time: 326.89s (5.44)
- Avg upload speed: 1.88MiB/s - max(2.84)
- Avg memory usage: 0.84GiB - max(0.84)
- Avg cpu usage: 2.68% - max(10.1)
- Avg throughput: 2964624 rows / 326.89 = 9069.3rows/s
PyArrow
Polars uses the Rust implementation of Arrow under the hood. With PyArrow we can quickly try it without any additional setup. I don't expect it to be much faster since I do not belive that Polars overhead is significant, let's try:
import pyarrow.parquet as pq CRATE_URI = 'crate://192.168.88.251:4200'table = pq.read_table("/data/taxi_01_24.parquet") BATCH_SIZE = 100_000 for batch in table.to_batches(BATCH_SIZE): batch.to_pandas().to_sql( 'ny_taxi', con=CRATE_URI, if_exists='append', index=False )
Results
- Time: 315.85s (5.26 minutes)
- Avg upload speed: 1.94MiB/s - max(2.68)
- Avg memory usage: 1.04GiB - max(1.12)
- Avg cpu usage: 3.19% - max(14.3)
- Avg throughput: 2964624 rows / 315.85 = 9386.04rows/s
Practically identical with Polars, at least in the metrics, the graph shows a different CPU pattern, ram and upload speed is very similar.
Parallelizing row groups
A common idea to improve performance further is to parallelize, but how can we parallelize reading different batches?
If we look at the parquet specification we see that data is logically split in Row groups so I think we can safely read different groups of data.
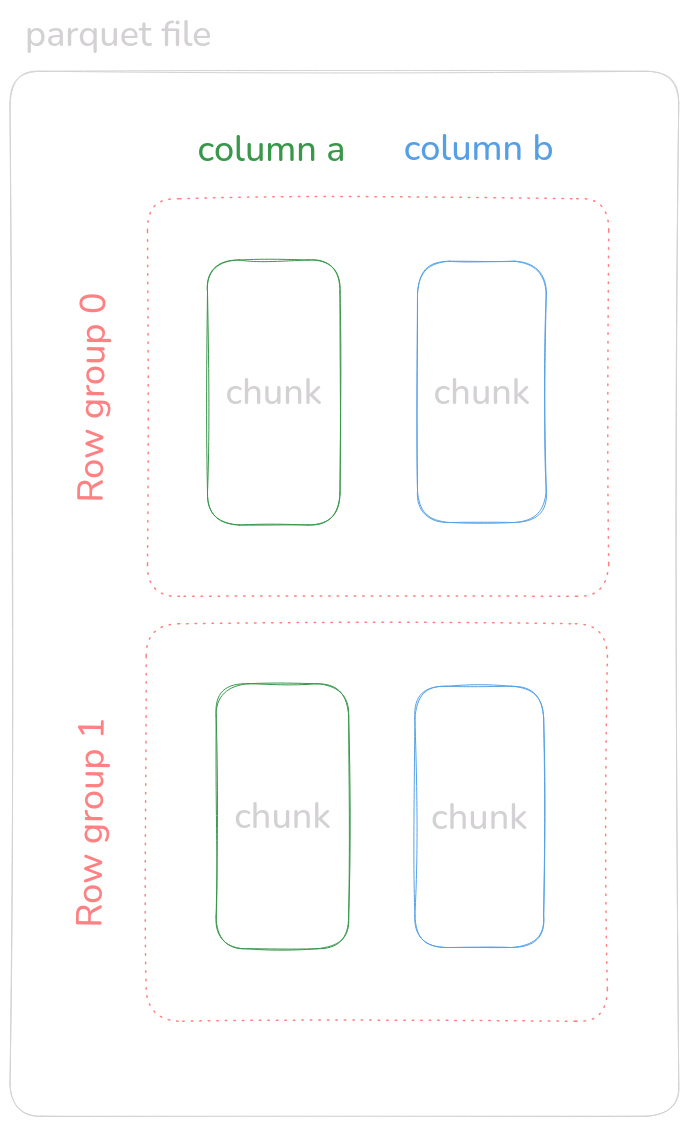
The idea is to have different threads access different row groups. They're dependent on the configured row group size and the file size, so if we have the file split in two groups, we could only theoretically get 2x improvement. At least in our first naive implementation.
I suspect that this is not the most efficient way of doing it, it is probably better to let whatever parquet reader implementation we use handle the reads for us. If we still want to read on row groups we could further split the reads on different ranges of rows within the row group, but let's try it.
For every row group, we are going to start a thread in a ThreadPoolExecutor and have it independently send data to the Database, leveraging PyArrow's pyarrow.ParquetFile.read_row_group method.
from concurrent.futures import ThreadPoolExecutor import pyarrow.parquet as pq CRATE_URI = 'crate://192.168.88.251:4200'file = pq.ParquetFile("/data/taxi_01_24.parquet") row_groups = file.num_row_groups def send_to_crate(row_group: int) -> None: f = file.read_row_group(row_group) for batch in f.to_batches(100_000): batch.to_pandas().to_sql( 'ny_taxi', con=CRATE_URI, if_exists='append', index=False ) with ThreadPoolExecutor(max_workers=6) as e: for row_group in range(row_groups): e.submit(send_to_crate, row_group)
Results
- Time: 164.69s (2.74 minutes)
- Avg upload speed: 3.78MiB/s - max(6.04)
- Avg memory usage: 1.45GiB - max(1.5)
- Avg cpu usage: 1.91% - max(5.7)
- Avg throughput: 2964624 rows / 164.69 = 18000.82rows/s
Results are way better than expected; almost half the time while maintaining a similar memory footprint, running 3 or 12 workers doesn't change much. We also almost double the throughput, from 9k to 18k rows/s
It makes sense since most of the work is I/O and the GIL is typically released on these operations, so the more threads we have waiting while sending bytes, the better.
While running this, I thought why not pass every batch to a different thread, it will theoretically use more memory, since batches will live longer in the pool as they’re waiting to get executed.
We're going to ignore row groups for a second.
from concurrent.futures import ThreadPoolExecutor import pyarrow.parquet as pq CRATE_URI = 'crate://192.168.88.251:4200'file = pq.ParquetFile("/data/taxi_01_24.parquet") def send_to_crate(batch): batch.to_pandas().to_sql( 'ny_taxi', con=CRATE_URI, if_exists='append', index=False ) with ThreadPoolExecutor(max_workers=12) as e: for batch in file.iter_batches(100_000): e.submit(send_to_crate, batch)
Results
- Time: 123.63s (2.06 minutes)
- Avg upload speed: 5.19MiB/s - max(9.99)
- Avg memory usage: 3.35GiB - max(3.6)
- Avg cpu usage: 4.8% - max(18.0)
- Avg throughput: 2964624 rows / 123.63 = 23979.33rows/s
Performance is better, memory composition goes up, if we use 24 workers we use more memory and get the same time, using 3 will use less memory and will take longer, 163s meaning we can tweak memory/time depending on the number of workers, for this dataset 12 seems to be good.
The next thing I can think of is combining both approaches, launching different processes, one for every row group, then batch it to the database with a threadpool.
from concurrent.futures import ThreadPoolExecutorfrom multiprocessing import Pool import pyarrow.parquet as pq CRATE_URI = 'crate://192.168.88.251:4200'file = pq.ParquetFile("/data/taxi_01_24.parquet") def send_to_crate(batch): batch.to_pandas().to_sql( 'ny_taxi', con=CRATE_URI, if_exists='append', index=False ) def read_parquet(row_group: int): f = file.read_row_group(row_group) with ThreadPoolExecutor(max_workers=12) as e: for batch in f.to_batches(50_000): e.submit(send_to_crate, batch) if __name__ == '__main__': with Pool(processes=file.num_row_groups) as pool: pool.map(read_parquet, range(file.num_row_groups))
Results
- Time: 90.60s (1.51 minutes)
- Avg upload speed: 7.12MiB/s - max(12.1)
- Avg memory usage: 4.73GiB - max(4.96)
- Avg cpu usage: 4.89% - max(15.7)
- Avg throughput: 2964624 rows / 90.60 = 32721.08rows/s
This is great, we have gone from 337 seconds to 90; ~3.78x faster!
But now what? I want better performance, 90 seconds still feels too much, and memory consumption is actually very high. We effectively traded memory for execution time (typical space over time tradeoff we see in algorithms).
I had two options, either think harder and see where I could gain more performance in Python and dive deper in to these APIs. Ultimately, I think that doing proper concurrency is going to be key, for that we currently can’t use Python because of the GIL, sure in recent versions they’re removing it, but I need proper concurrency now!
So how about?

It's gotta be easier, right?
Hold up cowboy! I showed up this article to a colleague, and he told me there is a way of doing it that I hadn't used, I internally mini-panicked thinking that I missed a pretty obvious one, luckily for the time invested into this article, it's less performant than Rust.
import pandasimport sqlalchemy as safrom sqlalchemy_cratedb.support import insert_bulk CRATE_URI = 'crate://192.168.88.251:4200'FILE_PATH = '/data/taxi_01_24.parquet'TABLE_NAME = 'taxi_pueblo' # Create a pandas DataFrame, and connect to CrateDB.df = pandas.read_parquet(FILE_PATH)engine = sa.create_engine(CRATE_URI) # Insert content of DataFrame using batches of records.df.to_sql( name=TABLE_NAME, con=engine, if_exists="replace", index=False, chunksize=50_000, method=insert_bulk,)
Results
- Time: 61.57s (1.03 minutes)
- Avg upload speed: 4.59MiB/s - max(9.93)
- Avg memory usage: 2.87GiB - max(2.91)
- Avg cpu usage: 3.13% - max(11.9)
- Avg throughput: 2964624 rows / 61.57 = 48147.53rows/s
It sort of makes sense that performs well, the insert_bulk function overrides the actual function that is used to send data, and changes it to leverage the http bulk args option that CrateDB has. Unfortunately, we cannot apply this to Polars as easily as Pandas, without monkey patching.
Rust, happened.
We are going to re-use some code that I wrote in CrateDBx, it's a project I started to try to ingest data to CrateDB in the most efficient way possible from different sources.
Tokio
Using tokio (async) to load the parquet in batches as we did in #2
Results
- Time: 60.07s
- Avg upload speed: 5.65Mb/s - max(16.18)
- Avg memory usage: 1.08Gb - max(1.09)
- Avg cpu usage: 2.21% - max(6.1)
- Avg throughput: 2964624 rows / 60.07 = 49352.68rows/s
Slightly faster than Pandas, the main difference is that it's able to send much bigger batches, hence the big peaks in upload speed.
Rayon
Rayon is a data-parallelism library, think real multi-threading unlike Python, what we are going to do is open a stream of batches, and create a thread for every batch, then every thread will read the batch, deserialize it to native rust types and serialize back to a string to be sent over HTTP using the bulk args parameter.
fn main(){ let batch_size = 20000; let file = File::open( "/home/surister/RustroverProjects/cdctest/data.parquet" ).unwrap(); let builder = ParquetRecordBatchReaderBuilder::try_new(file) .unwrap().with_batch_size(batch_size); let mut reader = builder .build() .unwrap(); let batches = reader.collect(); batches.into_par_iter().for_each(|batch| { let r = batch.unwrap(); let columns: Vec<_> = r .schema() .fields() .iter() .map(|field| field.name().clone()) .collect(); let records = record_batch_to_cvalues(r); let rows = cvalues_column_to_rows(records); cratedb.send_batch_http_sync( "doc", "taxi_rayon", &columns, rows ); });}
Results
- Time: 34.54s (0.57 min)
- Avg upload speed: 8.54MiB/s - max(45.68)
- Avg memory usage: 1.95GiB - max(1.97)
- Avg cpu usage: 3.45% - max(21.4)
- Avg throughput: 2964624 rows / 34.54 = 85825.17rows/s
Fantastic results.
Getting fancy
For this last one, we will try to leverage the entire 24 cores. In arrow we can skip pages when reading a specific range of rows, so we are going to calculate a range of rows and assign them to a thread.
cpu_cores / total_rows -> 2_964_624 / 24 = 123_526 rows
Every thread will open a ParquetRecordBatchReaderBuilder with ranges like:
(rows * i, rows * (i + 1))
- i=1; (123526 * 0, 123526 * 1)
- i=2; (123526 * 1, 123526 * 2)
- i=3; (123526 * 2, 123526 * 3)
and send batches of 20k to the database.
fn main(){ let file = File::open("/data_id.parquet").unwrap(); let row_count = ParquetRecordBatchReaderBuilder::try_new(file) .unwrap() .metadata() .file_metadata() .num_rows(); let cpu_cores = 24; let batch_size = 20000; let rows_per_group = row_count / cpu_cores; let remainder = row_count % cpu_cores; (0..cpu_cores).into_par_iter().for_each(|i| { println!("Processing core {}", i); let low_end = rows_per_group * (i); let mut high_end = rows_per_group; // last core will always send the remainder. if i == (cpu_cores - 1) { high_end += remainder; } let thread_id = thread::current().id(); let file = File::open("/data.parquet").unwrap(); let selectors = vec![ RowSelector::skip(low_end as usize), RowSelector::select(high_end as usize), ]; // creating a selection will combine adjacent selectors let selection: RowSelection = selectors.into(); let builder = ParquetRecordBatchReaderBuilder::try_new(file) .unwrap() .with_row_selection(selection) .with_batch_size(batch_size); let parquet_schema = builder.parquet_schema(); let mut reader = builder .build() .unwrap(); while let Some(rows) = reader.next() { let r = rows.unwrap(); let columns = r .schema() .fields() .iter() .map(|field| field.name().clone()) .collect(); println!("record batch gotten {:?}, from {:?}", r.num_rows(), thread_id); let records = record_batch_to_cvalues(r); let rows = cvalues_column_to_rows(records); cratedb.send_batch_http_sync( "doc", "taxi_superfast", &columns, rows ); } });
Results
- Time: 36.56s (0.60min)
- Avg upload speed: 11.58MiB/s - max(146.22)
- Avg memory usage: 1.89GiB - max(1.91)
- Avg cpu usage: 1.46% - max(2.6)
- Avg throughput: 2964624 rows / 36.56 = 81097.1rows/s
Time is pretty much the same it just changes the profile of upload speed, running this several time yields similar results, not too much difference with the last one, maybe ~34s is the best we can do with 3M rows, and with more data we would start seeing the difference between rayon methods.
Conclusion
We went from 316.90s to 34s, not too bad, still more testing could be done, with different datatypes and row numbers. On the rust side, there are things that can be optimized, when we deserialize data we wrap every value into a different Enum, this usually matters when the number of rows is very big. We then serialize to a string again from the native rust types, it'd be more efficient to just serialize directly the arrow arrays.
The main takeaway is that there is still a lot of things we can do on the client side to make things faster, we hardly ever leverage parallelism, smart data access or zero-copy techniques, we often ask open source developers to make their software faster, but maybe we should have a deeper look at how we build clients to said software.
Here is a table with every result compiled:
| method | time (s) | rows/s | avg upload speed (MiB) | Avg mem (GiB) |
|---|---|---|---|---|
| polars | 316.90 | 9355 | 1.93 | 6.3 |
| polars_batched | 315.88 | 9385 | 1.94 | 0.96 |
| arrow | 315.85 | 9386 | 1.94 | 1.04 |
| arrow_rgroups | 164.69 | 18000 | 3.78 | 1.45 |
| arrow_threadpool | 123.63 | 23979 | 5.19 | 3.35 |
| arrow_rgroups_threadpool | 90.60 | 32721 | 7.12 | 4.73 |
| pandas_insert_bulk | 61.57 | 48147 | 4.59 | 2.87 |
| tokio | 60.07 | 49352 | 5.65 | 1.08 |
| rayon | 34.54 | 85825 | 8.54 | 1.95 |
| rayon_fancy | 36.56 | 81097 | 11.58 | 1.89 |
If you are curious about how far CrateDB can go, these are the results of rayon with a couple of smaller tweaks, these tweaks are on the server side, we disabled replicas and set refresh time to 0.
Results
- Time: 19.52s (0.32)
- Avg upload speed: 20.16MiB/s - max(104.29)
- Avg memory usage: 1.89GiB - max(1.92)
- Avg cpu usage: 5.21% - max(13.3)
- Avg throughput: 2964624 rows / 19.52 = 151847.13rows/s
References
1. CrateDB developers "Performance" CrateDB documentation [Online.] Available: https://cratedb.com/docs/guide/performance/index.html
2. N. Schmidtmer. "How we scaled ingestion to one million rows per second," CrateDB Blog Accessed: Jun. 22, 2025. [Online.] Available: https://cratedb.com/blog/how-we-scaled-ingestion-to-one-million-rows-per-second
3. surister, "mylab/code/stats.py at master," GitHub repository *surister/mylab*. Accessed: Jun. 27, 2025. [Online.] Available: https://github.com/surister/mylab/blob/master/code/stats.py
4. M. Raasveldt, P. Holanda, T. Gubner, and H. Mühleisen, "Fair benchmarking considered difficult: Common pitfalls in database performance testing," in *Proc. Workshop on Testing Database Systems (DBTest ’18)*, Houston, TX, USA, 2018, pp. 1–6, doi: 10.1145/3209950.3209955.